Giuseppe Amatoa, Fausto Rabittib and Pasquale Savinoa
aIEI-CNR, Via S. Maria 46, 56126 Pisa,
Italy
G.Amato@iei.pi.cnr.it
and P.Savino@iei.pi.cnr.it
bCNUCE-CNR, Via S. Maria 36, 56126 Pisa,
Italy
F.Rabitti@cnuce.cnr.it
The wide diffusion of the World Wide Web (WWW) is making of vital importance the problem of effective retrieval of Web documents for casual as well as professional users. The complexity of Web documents is rapidly increasing with the wide use of multimedia components, such as images, audio and video, associated to the traditional textual content. This requires extended capabilities of the Web search engines in order to access documents according to their multimedia content. A large number of search engines (e.g. Altavista [Altavista], Yahoo [Yahoo], HotBot [HotBot] and [Lycos]) support indexing and content-based retrieval of Web documents but only the textual information is taken into account. Initial experimental systems providing support to the retrieval of Web documents based on their multimedia content (Webseek [6], [Webseek] and Amore [4], [Amore]) are limited to the use of pure physical features extracted from multimedia data, such as colour, shape, texture extracted from images. These systems do not go beyond the use of pure physical visual properties of the images, represented in feature vectors, therefore suffer the same severe limitations of today general-purpose image retrieval systems [5], such as Virage and QBIC [2,3]. These systems consider images as independent objects, without any semantic organisation in the database or any semantic inter-relationships between database objects.
The approach proposed in this paper tries to overcome the limits of existing systems making use of the information about the "context" in which a multimedia object (e.g., an image) appears: this contextual information includes the information contained in the same Web document where the multimedia object is contained, the information carried by other Web documents pointing to it, the (possible) internal structuring of the multimedia object (i.e., components of an image). This approach permits one to combine, during query processing, the result of efficient information retrieval techniques, working on text components, with less precise results of generalised feature based images search techniques, exploiting the inter/intra-relationships in WWW documents. To describe and make use of this potentially rich information, it is necessary to use a suitable model for the representation of multimedia Web documents. We have adopted the HERMES multimedia model [1], that is particularly suited to describe multimedia documents’ content in order to support content-based retrieval. In the HERMES model, multimedia objects are represented through features and concepts — concepts provide a description of the semantic content of the object, features provides a representation of physical aspects of the object — while the retrieval is based on the measure of similarity between the objects and the query.
We have implemented a prototype system that gathers documents from the Web and, after an analysis of its structure identifies the different types of data (e.g. text, images, audio, video) and "classifies" them. Textual information is used to extract the terms to be used for text retrieval purposes; images are analysed in order to compute the values of the physical visual features and to derive the presence of one of the pre-defined concepts.
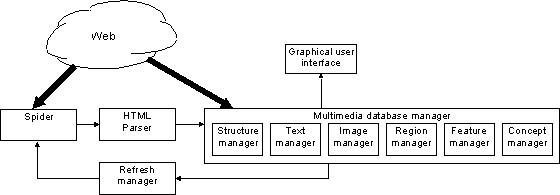
The prototype system (Fig. 1) that is presented in this paper addresses all phases of the retrieval of Web documents: it gathers documents from a predefined set of Web sites and analyses their content in order to derive the structure and to extract their content. The existing version uses only text and images. The extracted information is used to "classify" documents to provide support to their content-based retrieval. It is useful to observe that a Web document may contain references to other Web documents, as for instance images, or other multimedia objects. These multimedia documents are classified independently but the relationship with other documents that refer them is retained. Traditional IR text retrieval techniques are applied on the text part of the documents. Images are processed in order to extract their visual features; these features are used to support similarity retrieval; furthermore, a taxonomy of image categories has been created and the classification process automatically associates an image to one or more categories.
The system architecture is sketched in Fig. 1.
The user may interact with the search engine using a graphical Web interface. Similarity between images is computed by comparing the values of their features and of concepts that can be extracted from them. Retrieved images are presented in decreasing similarity values. They can be used as a starting point for successive similarity retrieval or, according to the information extracted from Web documents, to browse the database to retrieve similar documents.
In Fig. 2 an example of a query session is shown. In the example we assume that the user, looking at documents containing a person (this can be done by using a predefined concept "person") has retrieved the set of images shown in Fig. 2a. By choosing a particular image of the result, it is possible to have access to the information about the image itself (Fig. 2b): the address of pages that point to it, that contain it in-line, its regions. Using this information the user can inspect a page in which the image is contained in-line (Fig. 2c). The page is displayed together with information about the images referred, the images in-line, the pages pointed, and the pages that refer the page. Then, one of the referred images is accessed (Fig. 2d) together with all related information. The process can continue by using this image as a starting point for a query or to access the page that contains the image in-line.
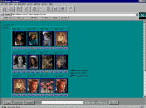
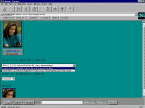
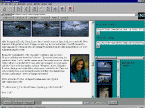
a) b) c) d)
Fig. 2. User interface.In this paper we presented a prototype of a search engine system for retrieval of Web documents using their multimedia content. The retrieval combines the use of text and images; in particular, images are retrieved using their visual features as well as semantic information. Similarity retrieval and browsing are supported.
This research has been funded by the EC ESPRIT Long Term Research program, project no. 9141, HERMES (Foundations of High Performance Multimedia Information Management Systems).
[1] G. Amato, G. Mainetto and P. Savino, An approach to a content-based retrieval of multimedia data, to appear in Multimedia Tools and Application.
[2] J.R. Bach, C. Fuller, A. Gupta, A. Hampapur, B. Horowitz, R. Humphrey, R. Jain and C.F. Shu, The Virage image search engine: An open framework for image management, in: Proceedings of the SPIE 96, 1996.
[3] M. Flickner et al., Query by image and video content: the QBIC system, IEEE Computer, 28(9), September 1995.
[4] S. Mukherjea, K. Hirata and Y. Hara, Towards a multimedia World Wide Web information retrieval engine, in: Proc. of the 6th WWW International Conference, S. Clara, CA, 6–11 May 1997.
[5] C. Meghini, F. Sebastiani and U. Straccia, Modelling the retrieval of structured documents containing texts and images, in: Proc. of the 1st ECDL, Pisa, Italy, September 1997.
[6] J.R. Smith and S. Chang, Visually searching the Web for content, IEEE Multimedia, July–September 1997.
[Altavista] http://www.altavista.com/
[Amore] http://www.ccrl.neclab.com/amore
[HotBot] http://www.hotbot.com/