|
ir. D.H. Lie Carp Technologies Hengelosestraat 174, 7521 AK Enschede |
This paper describes a system for automatic summary generation called Sumatra. It differs from other systems in being domain independent and, instead of relying on statistical techniques, it uses a Natural Language Processing approach, involving parsing, semantic analysis and text generation. The system has been evaluated by using final exam texts from the Dutch grammar school in summarizing. The main conclusion is that the Sumatra system is adequately capable of extracting the important information elements from a text.
Keywords: Language Technology, Automatic Text Summarization, Natural Language Understanding
This paper describes a system for automatic summary generation called Sumatra. This system has been developed entirely in the Java programming language during a M. Sc. Thesis at the University of Twente in collaboration with Medialab (Origin) [1].
First, a definition of a summary will be given (2). Next, the summarizing strategy used in Sumatra will be described (3). Finally, the evaluation of the system will be described (4) followed by the main conclusions (5).
Most summary definitions state in more or less words that a summary is simply an abbreviated version of a document. For example, [2] defines a summary as a condensation of the main ideas in an article and [3] defines it as a text reduced to its main points. Most summary definitions – like the ones above – contain a clause stating that a summary only contains the crucial information elements needed to understand the text. This is however not a very practical definition, because a summary needs to contain the information the user needs, and this information will not be the same for every user. Therefore, for the purpose of this document, I will define a summary as follows:
|
A summary is a selection from a collection of information elements. |
Definition 1 |
This definition however, does not mention the purpose of a summary. People use summaries in many different ways, and for each use a different type of summary exists [4]. I identify the following different summary types and purposes:
Summarizing can be done on the following three levels:
Dumb strategies only use the first one, while more sophisticated strategies should be capable of performing all three. Many sophisticated strategies however, are domain dependent which limits them to texts about a specific topic.
Unlike most other sophisticated strategies, the Sumatra system uses a domain independent strategy, which consists of the following steps:
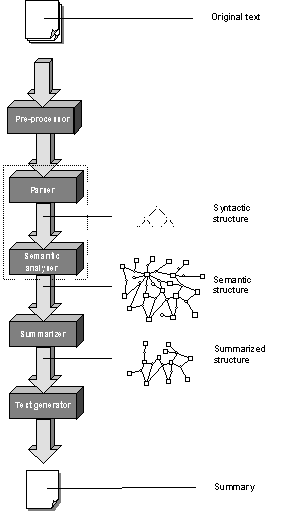
The Sumatra system uses the following architecture to perform these steps:
Figure 1 – Architecture of the Sumatra system
The input of the system consists of a text. The output consists of a summarized version of that text. Let’s take a closer look at the different components of the system.
Pre-processor
Before a text can be processed it has to be pre-processed. This task consists of segmenting the text into paragraphs, sentences and words, and looking up the words in a lexicon.
Parser
The parser analyzes the input text and generates a syntactic structure. Furthermore, the parser uses a rewrite strategy during parsing to reduce the complexity of a sentence and restates it in fewer words [5].
Semantic analyzer
This component uses the output of the parser to build a meaning representation of the text: a semantic structure. Note that in the Sumatra system, the parser and the semantic analyzer are put together in the same component.
Summarizer
The summarizer takes a semantic structure and prunes it in such a way that the most important parts remain.
Text generator
The text generator uses the output of the summarizer – a summarized semantic structure – to generate a new text. Furthermore, the text generator is responsible for the aggregating of sentences.
The rest of this document will only discuss the semantic analysis and the summarization step.
A text can be viewed as a collection of relations between objects. For example, the sentence "John gives Mary a book." denotes some relation between the objects "John", "Mary", and "a book". The goal of the semantic analysis is to identify these relations, and store them in a semantic structure:
John gives Mary a book.
à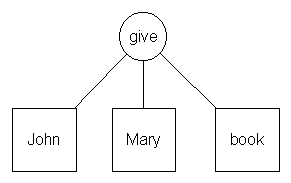
Example 1 – Conversion between sentence and relation
If the semantic analyzer identifies a relation, it is stored in a semantic structure. If a node already exists, it will not be stored twice, but shared, resulting in a semantic network of objects and relations.
Because the semantic analyzer emits a semantic structure in the form of a graph, the task of omitting information can be considered as pruning in this graph.
A relation oriented graph-pruning method selects certain relations from a semantic structure, together with their arguments, and discard the rest of the structure. Figure 2 shows the selection of relation A and the resulting summarized structure.
![]()
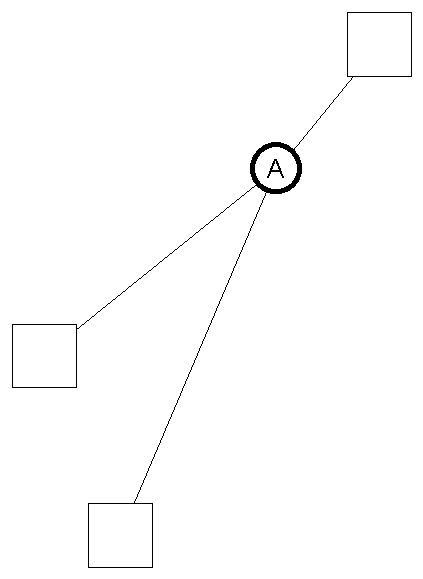
Figure 2 – The selection of a relation
Prior to selecting relations, some algorithm must be used to decide which relations to select. Such an algorithm could assign an importance value to each relation, and discard all relations with an importance value below a certain threshold, or select n relations with the highest importance value, and discard the rest of the structure. Either method uses an importance value.
There are several ways to define the importance value of a relation. A possible definition could use the connectivity of a relation as its importance value. The connectivity of a relation is defined as the number of connections that must be severed to cut the relation and all its arguments free from the structure. Consider, for example, the following semantic structure:
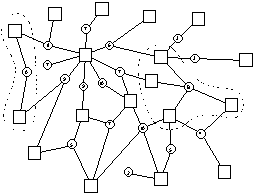
Figure 3 – The connectivity of a relation
The numbers inside the relations indicate their connectivity. Relation A has a connectivity of 2 and thus an importance value of 2, whereas relation B has a connectivity of 8. When using connectivity as a definition of importance, relation B is more important than relation A. This can be defined as follows:
| The importance value v of a relation r equals the sum of the degrees of r’s arguments minus the number of r’s arguments. |
Or, more formally:
Let r be the relation and n its number of arguments
importance(r)= – n
argumentDegree(r,x)=The degree of r’s xth argument
Using Definition 2, let’s select the six most important relations and discard the rest. This would result in the following structure:
![]()
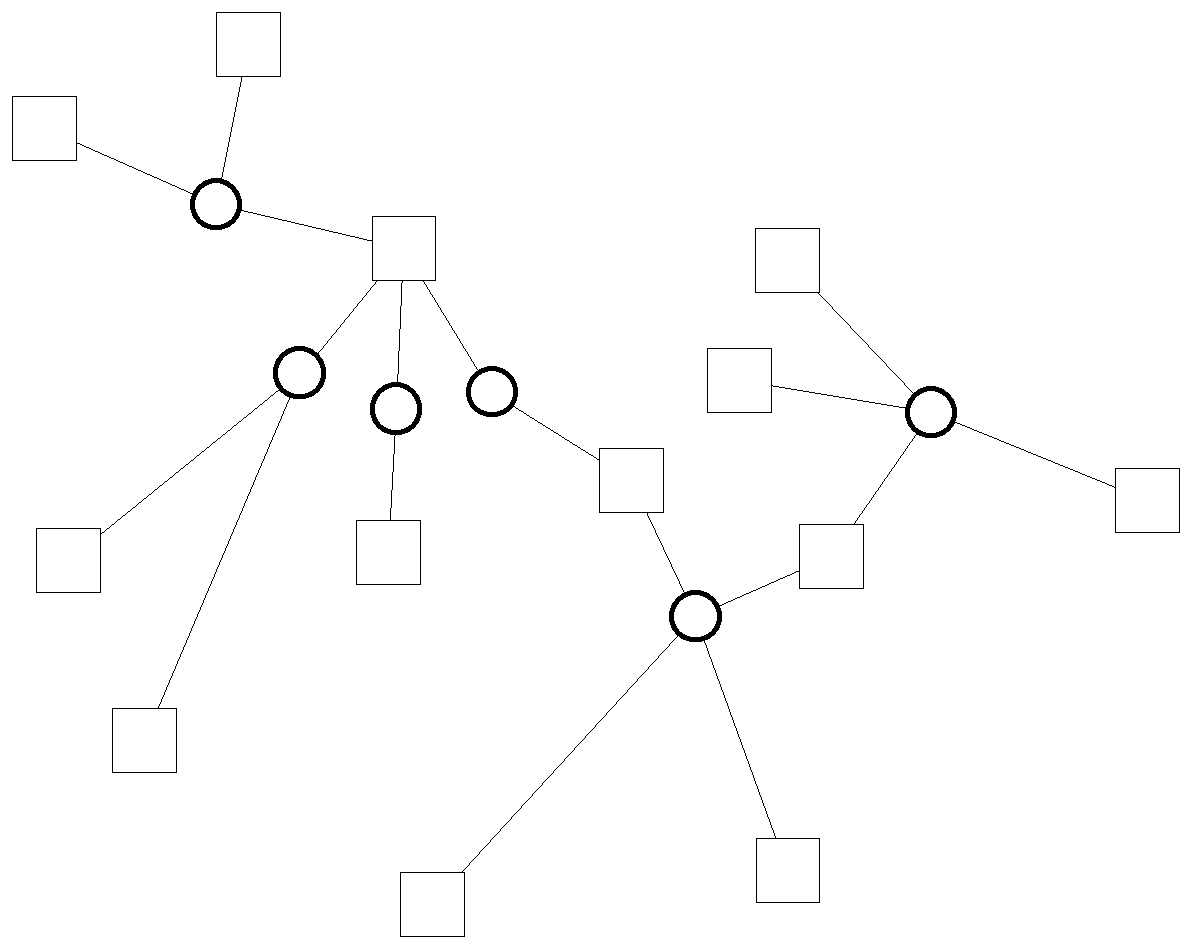
Figure 4 – Selecting the six most important relations using Definition 2.
Beside connectivity, other parameters can be used to determine the importance value of a relation. The first and last sentence of a paragraph are usually more important than other sentences, and the occurrence of certain signal words in a sentence can indicate that it is important. The importance value of relations that have been derived from such sentences can be altered by multiplying it with a certain boost factor. The Sumatra system uses the following heuristics to alter the importance value if a relation conforms to certain conditions:
Condition |
Boost factortor |
|
First sentence of a paragraph |
4 |
|
Last sentence of a paragraph |
4 |
|
Contains an enumeration signal word* |
4 |
|
Contains a quantor signal word* |
1.5 |
|
Contains a signal word* |
2 |
| Contains an example signal word |
0.5 |
*
Only one of these boost conditions are applied to a relationThe values for these boost factors have been obtained by extensive testing with six texts used in the final exams of the Dutch grammar school. For each text, a list of the relevant information elements was available and a script has been used to automatically determine the percentage of relevant information elements a summary contains. The values for the boost factors have been varied to maximize this percentage. The combination of values for the boost factors have been chosen manually, and because of the enormous search space of this optimizing problem, it is very likely that a better combination exists. A better combination could be found by using a neural network or genetic algorithm to find a higher (local) maximum.
Instead of selecting relations, a node-oriented graph pruning method selects certain nodes from a semantic structure, together with the relations they participate in, and the other arguments of these relations. The rest of the structure will be discarded. Figure 5 shows the selection of node A and the resulting summarized structure:
![]()
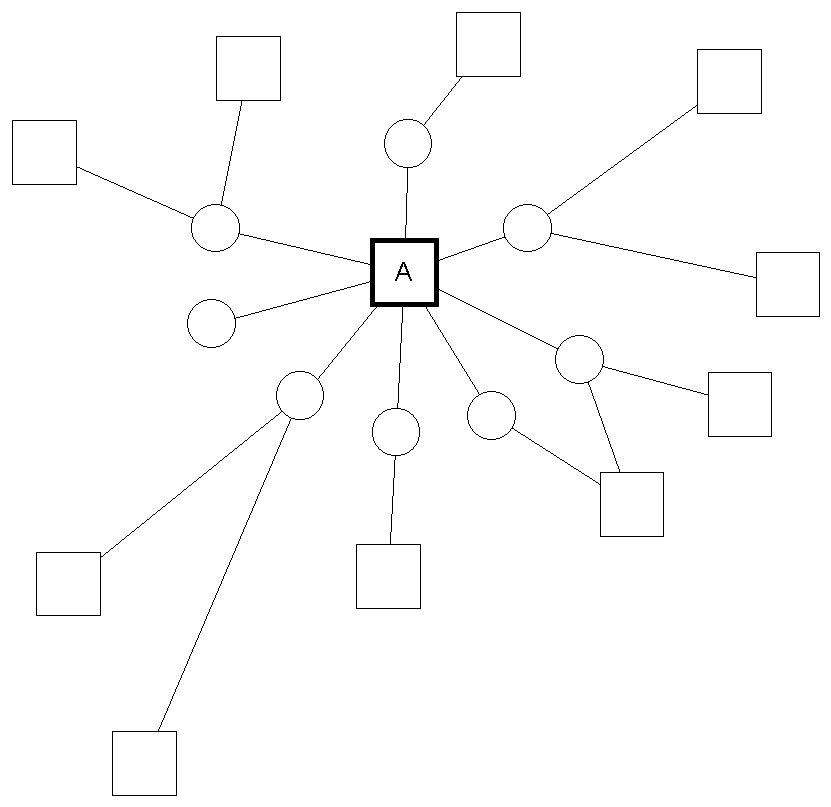
Figure 5 – The selection of a node
Just like in the relation-oriented method, an importance value must be defined to decide which nodes to select. Using the connectivity thought, one could easily define the importance value of a node as its degree:
|
The importance value v of a node n equals the degree of n |
Definition 3 |
Although this node-oriented graph pruning method seems more flexible than the relation-oriented method – because the user can easily interact with it – it does not provide much control over the size of the summarized structure. When the user selects an extra node, all relations that include this node as an argument are added to the structure, whereas the relation-oriented method provides a more granular control over the number of relations. A hybrid approach however, is possible and can give us the best of both worlds.
Among other things, the Sumatra system has been evaluated by letting it summarize some final exam texts from the Dutch grammar school in summarizing. The following graph lists the results of this evaluation.
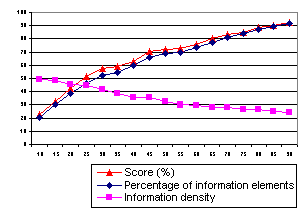
The results have been obtained by using the official solutions for the final exams. These solutions contain all relevant information elements and their importance. Using these importance values, a score have been calculated. As can be seen in the graph above, the score is higher than the percentage of information elements. This indicates that the Sumatra system favors important information elements above less important ones.
Furthermore, the graph shows that the Sumatra system is able to extract almost 50% of the relevant information elements when the summary size is set to 25% of the original.
It is feasible to build a functional domain independent automatic summary generation system. Furthermore:
References
D.H. Lie, Automatic Summary Generation: a Natural Language Processing approach (M. Sc. Thesis), University of Twente, 1998.